大数据没那么远:把散乱数据理顺,让业务敢用
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
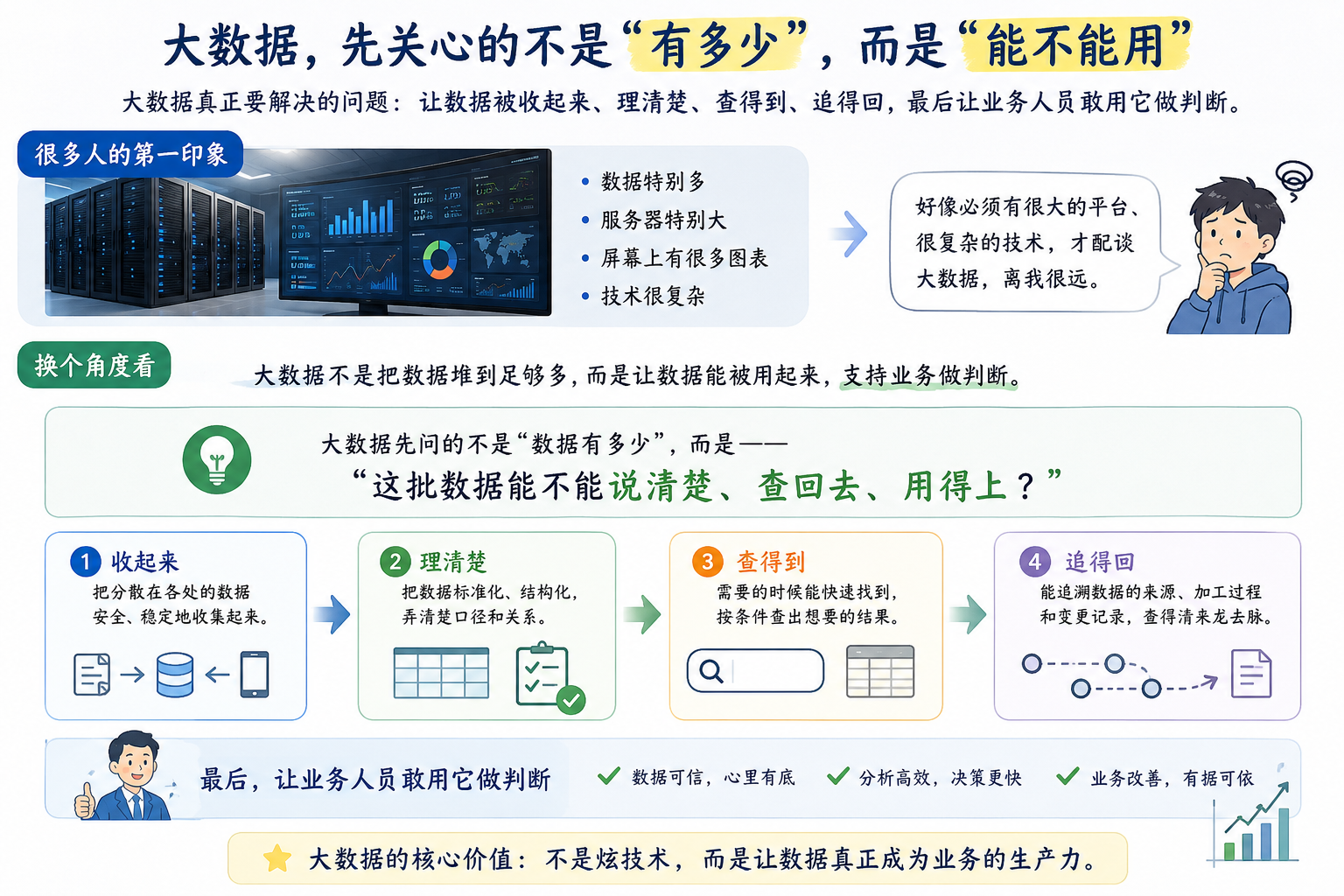
很多人第一次听到“大数据”,脑子里会冒出一个画面:数据特别多,服务器特别大,屏幕上有很多图表。 这很正常。很多项目讲大数据时,确实喜欢从这些东西讲起。 只是如果只看到这些,人很容易觉得大数据离自己很远。好像必须有很大的平台、很复杂的技术,才配谈这件事。 其实可以先放轻一点。 大数据真正要解决的问题,不是把数据堆到足够多。它更关心这些数据能不能被收起来、理清楚、查得到、追得回,最后让业务人员敢用它做判断。 如果把大数据讲成人话,它先问的不是“数据有多少”,而是“这批数据能不能说清楚、查回去、用得上”。
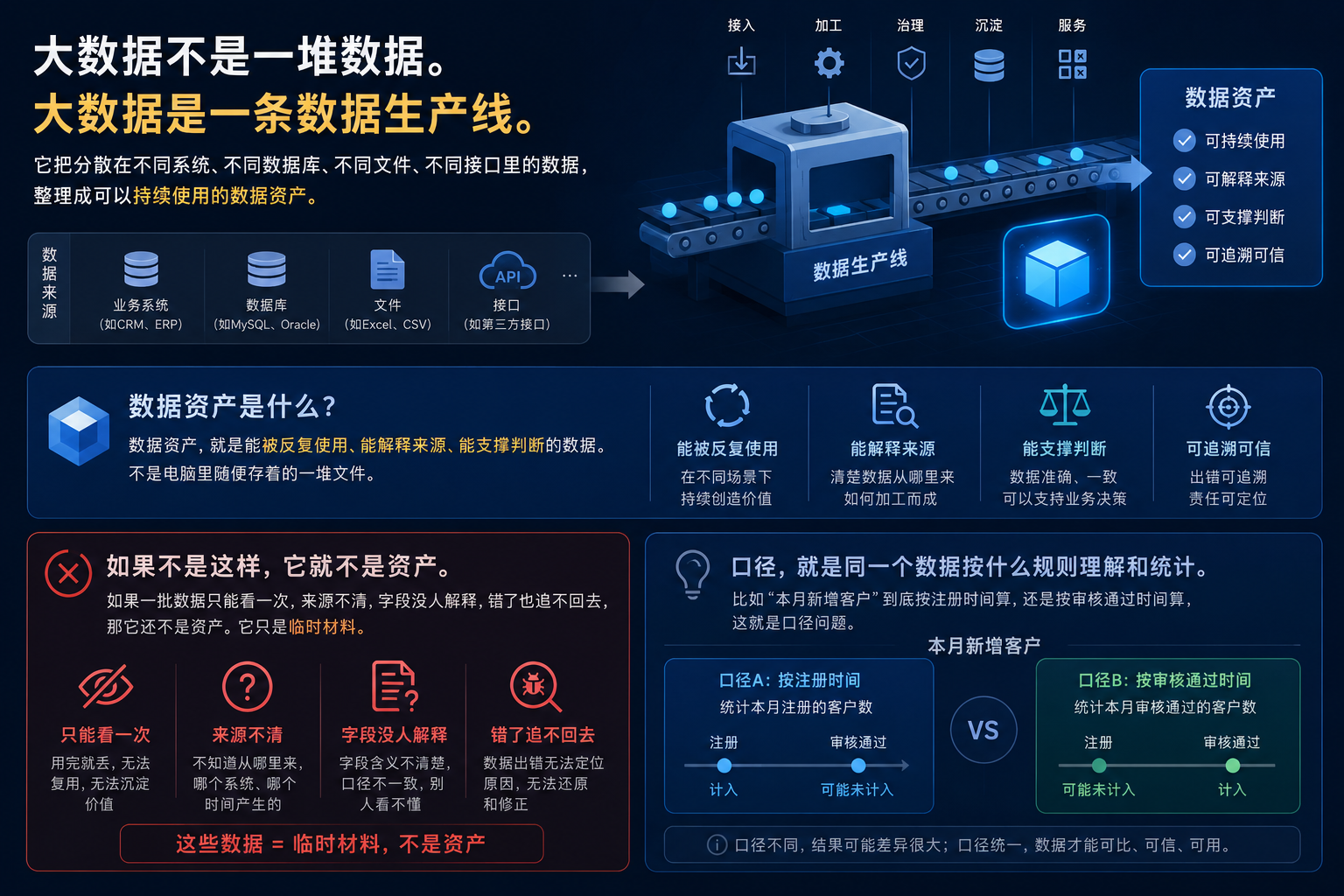
一句话先说清楚大数据不是一堆数据。 大数据是一条数据生产线。 它把分散在不同系统、不同数据库、不同文件、不同接口里的数据,整理成可以持续使用的数据资产。 数据资产,就是能被反复使用、能解释来源、能支撑判断的数据。不是电脑里随便存着的一堆文件。 如果一批数据只能看一次,来源不清,字段没人解释,错了也追不回去,那它还不是资产。它只是临时材料。 口径,就是同一个数据按什么规则理解和统计。比如“本月新增客户”到底按注册时间算,还是按审核通过时间算,这就是口径问题。
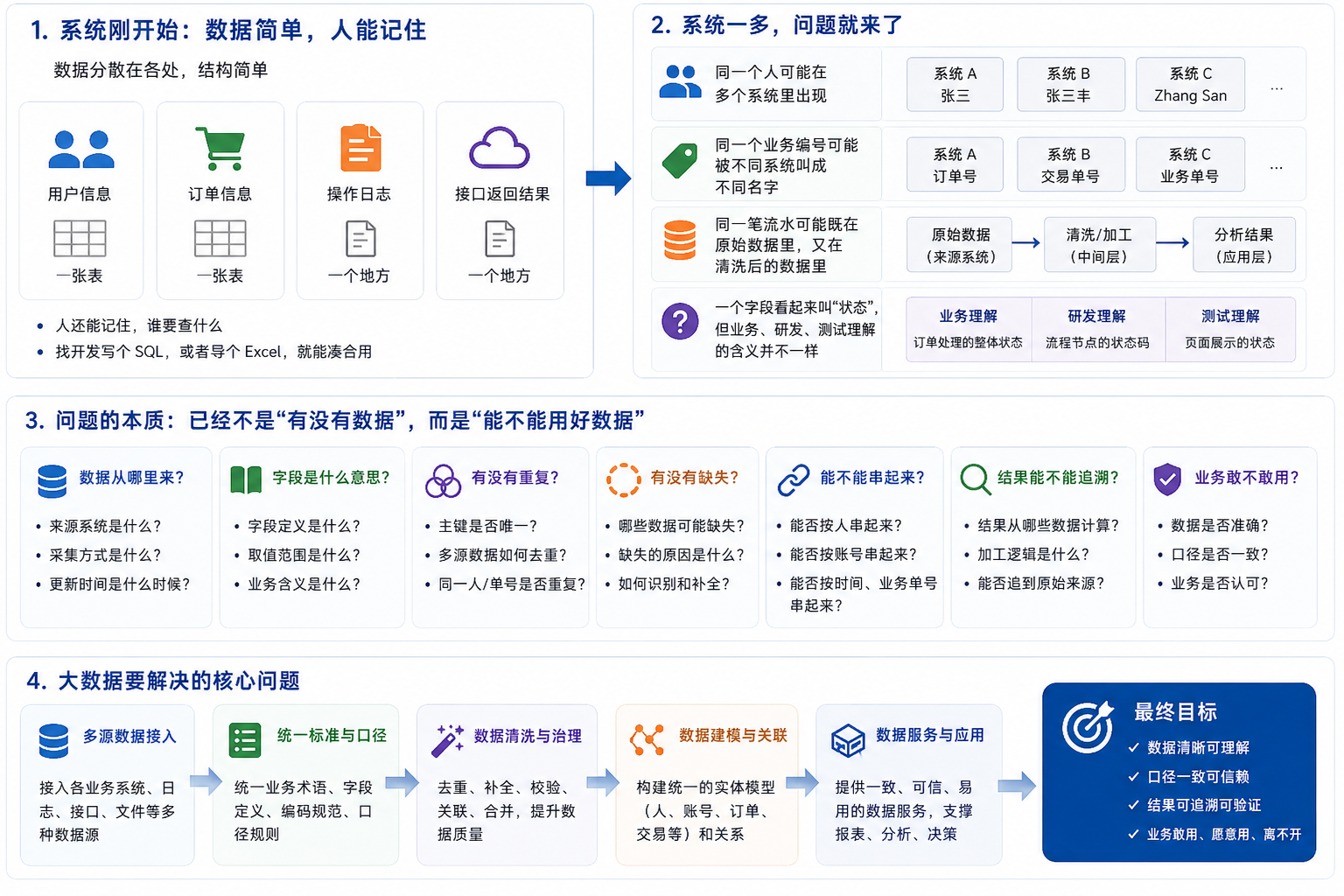
为什么很多系统会需要大数据一个业务系统刚开始做的时候,数据通常不复杂。 用户信息放一张表。 订单信息放一张表。 操作日志放一个地方。 外部接口返回结果再放一个地方。 刚开始人还能记住。谁要查什么,找开发写个 SQL,或者导个 Excel,就能凑合用。 但系统一多,问题就来了。 同一个人可能在多个系统里出现。 同一个业务编号可能被不同系统叫成不同名字。 同一笔流水可能既在原始数据里,又在清洗后的数据里。 一个字段看起来叫“状态”,但业务、研发、测试理解的含义并不一样。 这时候,问题已经不是“有没有数据”。 问题变成了: 数据从哪里来? 字段是什么意思? 有没有重复? 有没有缺失? 能不能按人、账号、时间、业务单号串起来? 结果能不能追到原始来源? 业务人员敢不敢拿这个结果做判断? 大数据要解决的,就是这些问题。
大数据不是报表系统很多项目会把大数据理解成报表。 这个理解也容易走偏。 报表只是大数据的一种输出。真正有价值的是报表背后的数据整理过程。 比如一个页面上展示“本月新增 1000 条业务记录”。这个数字看起来简单,但背后要回答很多问题。 这 1000 条从哪些系统来? 有没有重复计算? 统计时间按创建时间,还是按审核通过时间? 被撤回、作废、重复录入的数据算不算? 明天再查一次,结果会不会变? 如果这些问题答不上来,报表再漂亮,也只能看个热闹。 所以,大数据不是把图表做炫。 大数据是让数据结果经得起追问。
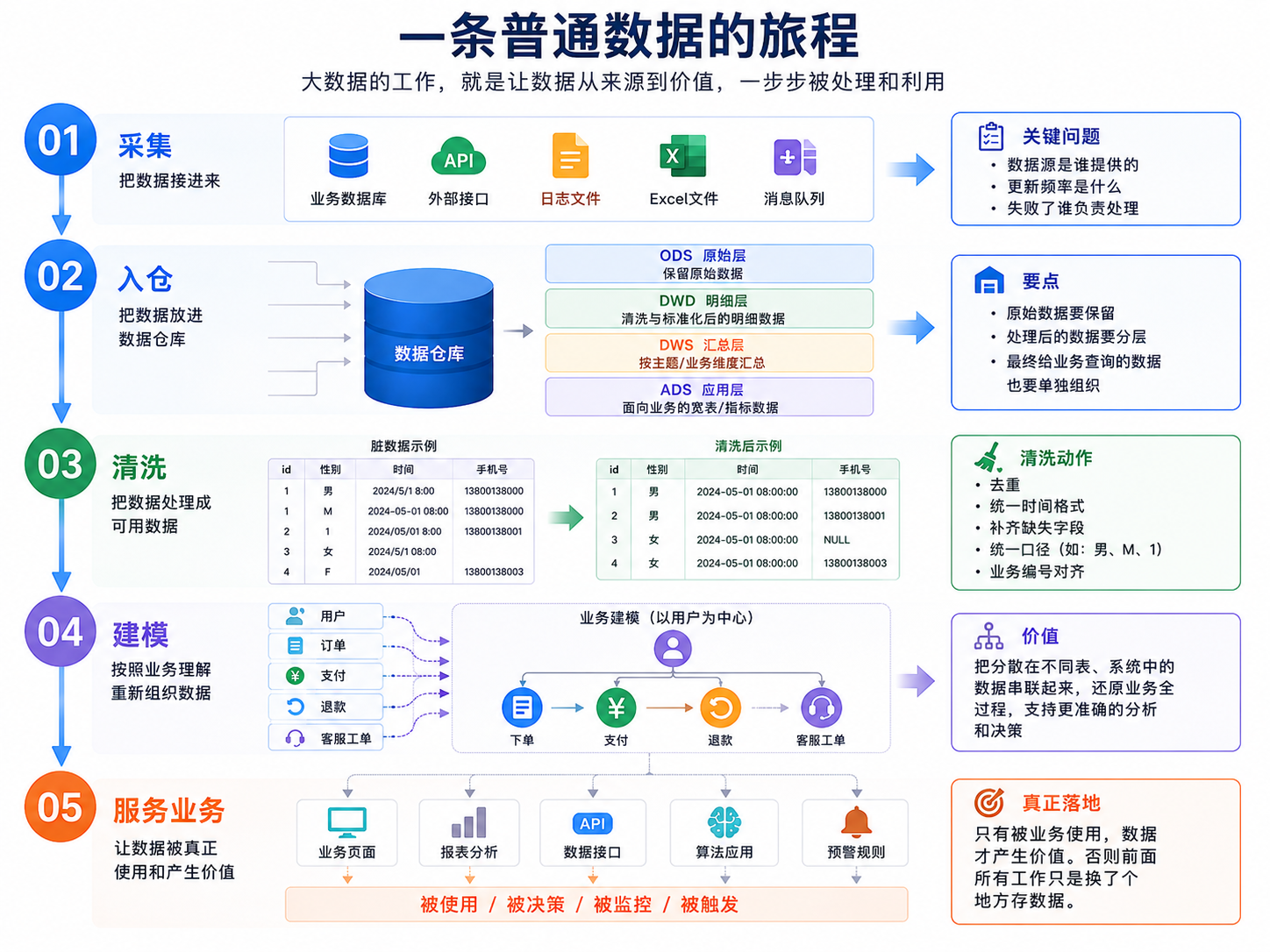
一条数据通常要走几步大数据的工作,可以用一条普通数据的旅程来理解。 第一步,采集。 采集就是把数据接进来。来源可能是业务数据库、外部接口、日志文件、Excel 文件,也可能是消息队列。 这一步要先问清楚:数据源是谁提供的,更新频率是什么,失败了谁负责处理。 第二步,入仓。 入仓,就是把数据放进数据仓库。数据仓库是专门用来集中保存、整理和分析数据的数据库体系。 这里不能只把数据随便塞进去。原始数据要保留,处理后的数据要分层,最终给业务查询的数据也要单独组织。 第三步,清洗。 清洗不是把数据洗漂亮,而是把脏数据处理成可用数据。 比如去掉重复数据,统一时间格式,补齐缺失字段,把“男、M、1”统一成同一种性别口径,把不同系统里的业务编号对齐。 第四步,建模。 建模在这里不是大模型训练。它指的是按照业务理解重新组织数据。 比如把用户、订单、支付、退款、客服工单串起来。这样查询时看到的不再是孤立字段,而是一件事的完整过程。 第五步,服务业务。 数据整理好之后,要能被页面、报表、接口、算法、预警规则使用。 这一步才是真正的落地。否则前面做再多,也只是把数据换了个地方存。
ODS、DIM、DWD、DWS、ADS 到底是什么很多人一看到 ODS、DIM、DWD、DWS、ADS 就头大。 其实可以先按人话理解。 ODS 是原始数据层。它尽量保留数据刚进来时的样子,方便以后追溯来源。 DIM 是维度层。维度,就是看数据的角度,比如人、机构、地区、时间、商品、客户。 维度层的作用,是把这些常用信息整理成统一口径。这样不同报表、不同接口、不同分析任务,就不用各自维护一套“客户是谁、地区怎么分、机构怎么归属”的规则。 DWD 是明细数据层。它会对原始数据做清洗和标准化,让字段更统一,数据更适合继续使用。 DWS 是汇总数据层。它开始按业务主题做统计,比如按用户、订单、地区、时间做汇总。 ADS 是应用数据层。它直接面向页面、报表、接口或业务分析,通常已经贴近具体使用场景。 这 5 层不是为了显得专业。 它们的作用是把“原始数据、公共维度、清洗明细、汇总数据、业务使用数据”分开。这样出了问题,能一层一层往回查。 不同团队的叫法会有差异。有的团队会把 DIM 单独算一层,有的团队会把它当成公共维度表放在数仓中间。普通读者不用先纠结名字,先记住它解决的是“按什么角度看数据”的问题。 没有分层,数据就容易变成一锅粥。
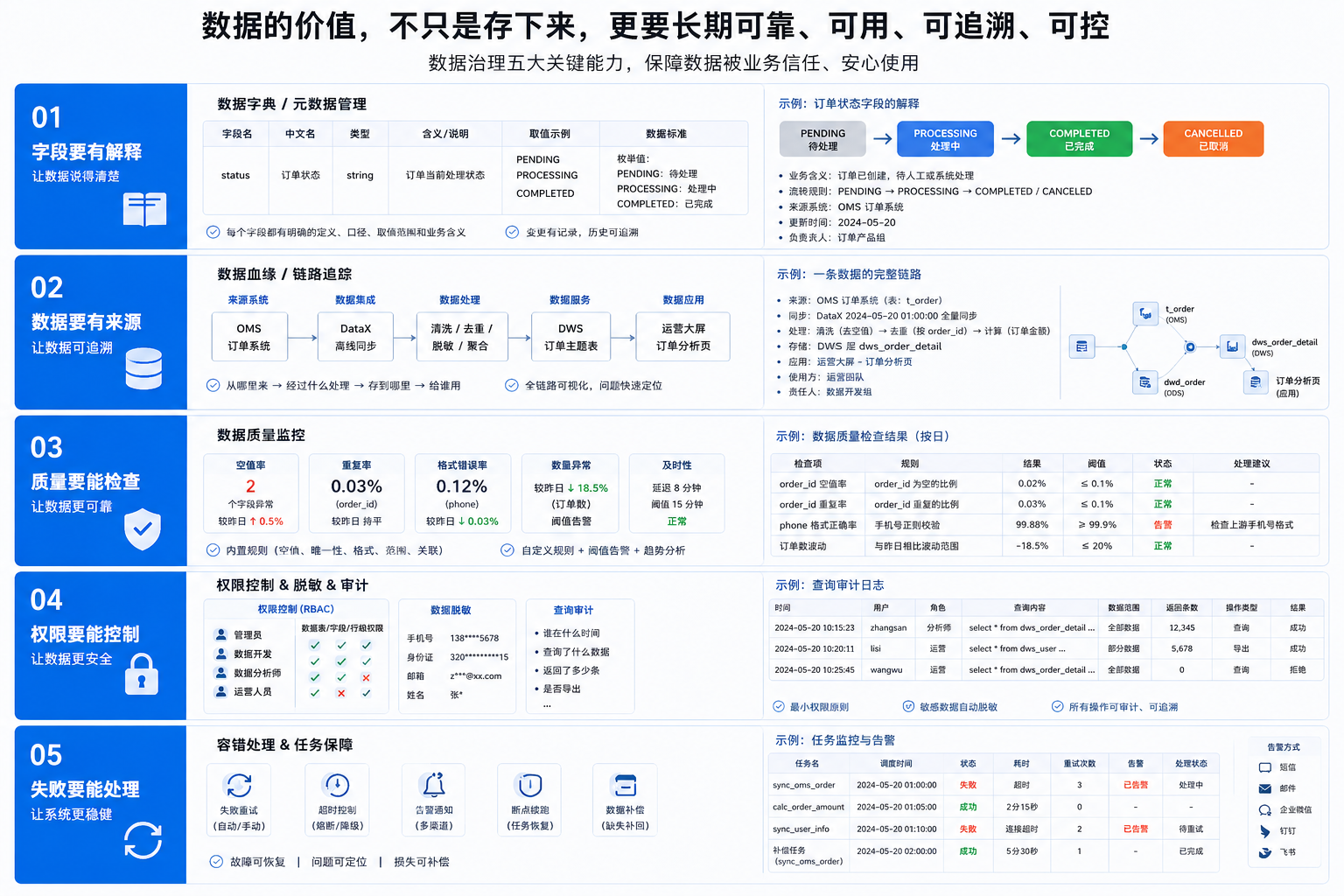
真正难的不是存数据现在存数据并不稀奇。 真正难的是让数据长期可靠。 第一,字段要有解释。 一个字段叫 第二,数据要有来源。 一个结果从哪个系统来,经过哪些处理,最后给哪个页面用,都要能追。 第三,质量要能检查。 空值、重复、格式错误、数量异常,这些不能靠人肉发现。 第四,权限要能控制。 不是所有人都适合看到所有数据。敏感字段要脱敏,查询行为要留痕。 第五,失败要能处理。 数据同步失败、接口超时、任务中断,都要能重试、能告警、能补偿。 这些东西听起来不如“大屏”“算法”“模型”热闹,但它们决定了大数据能不能真的被业务信任。
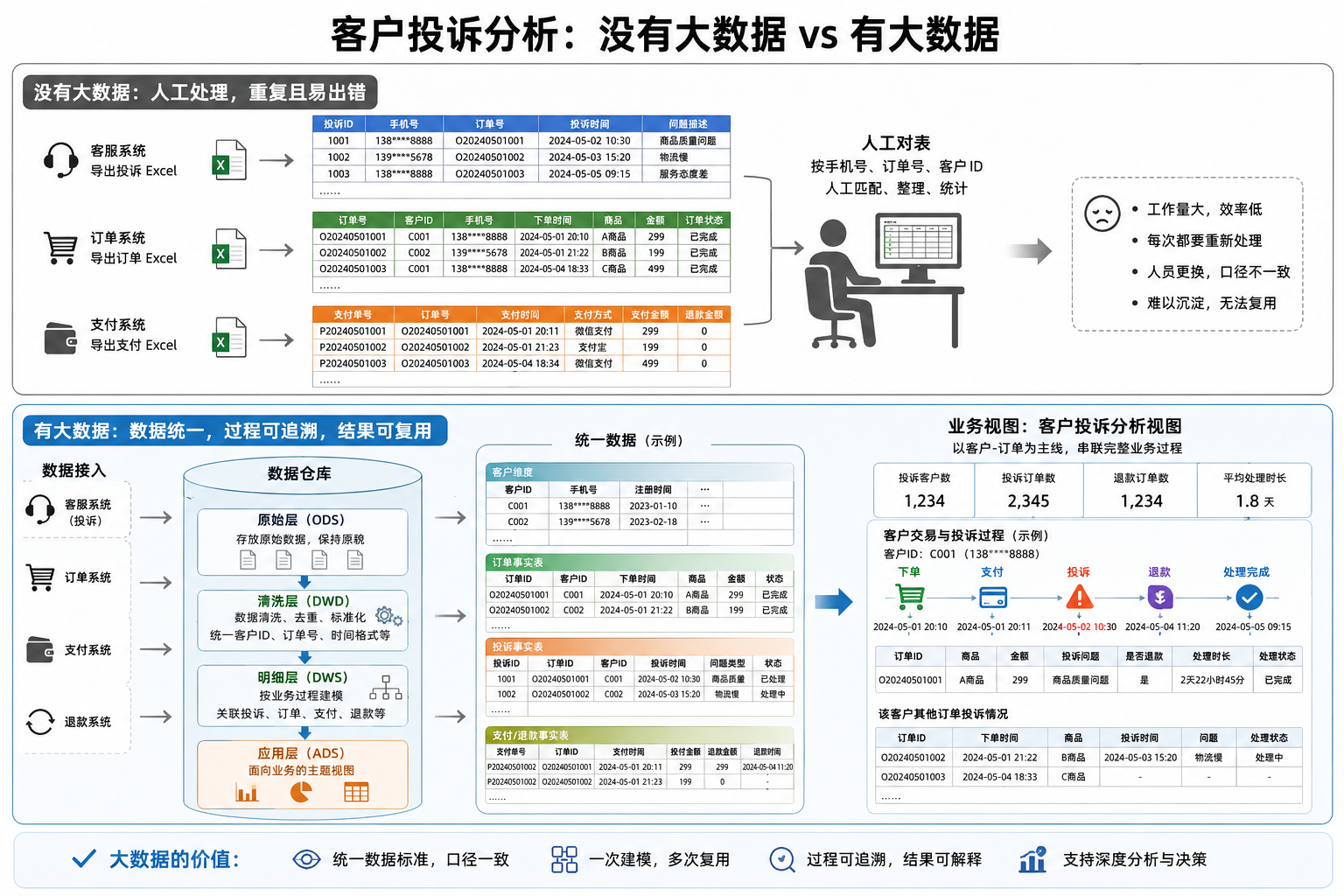
一个简单例子假设一个公司想分析客户投诉。 如果没有大数据,可能会这样做: 客服系统导一份投诉 Excel。 订单系统导一份订单 Excel。 支付系统再导一份支付 Excel。 然后人工把手机号、订单号、客户 ID 对一遍。 这能做,但很累,而且每次都要重来。 更麻烦的是,换一个人来做,口径可能就变了。 大数据的做法是先把这些数据接进数据仓库。 原始投诉记录放原始层。 清洗后统一客户 ID、订单号、时间格式。 再把投诉、订单、支付、退款这些数据按客户和订单串起来。 最后输出一个业务视图:某个客户在什么时间买了什么,什么时候投诉,投诉前后有没有退款,处理用了多久。 这样业务人员看到的就不是几张散表,而是一条能解释的业务过程。 这就是大数据的价值。
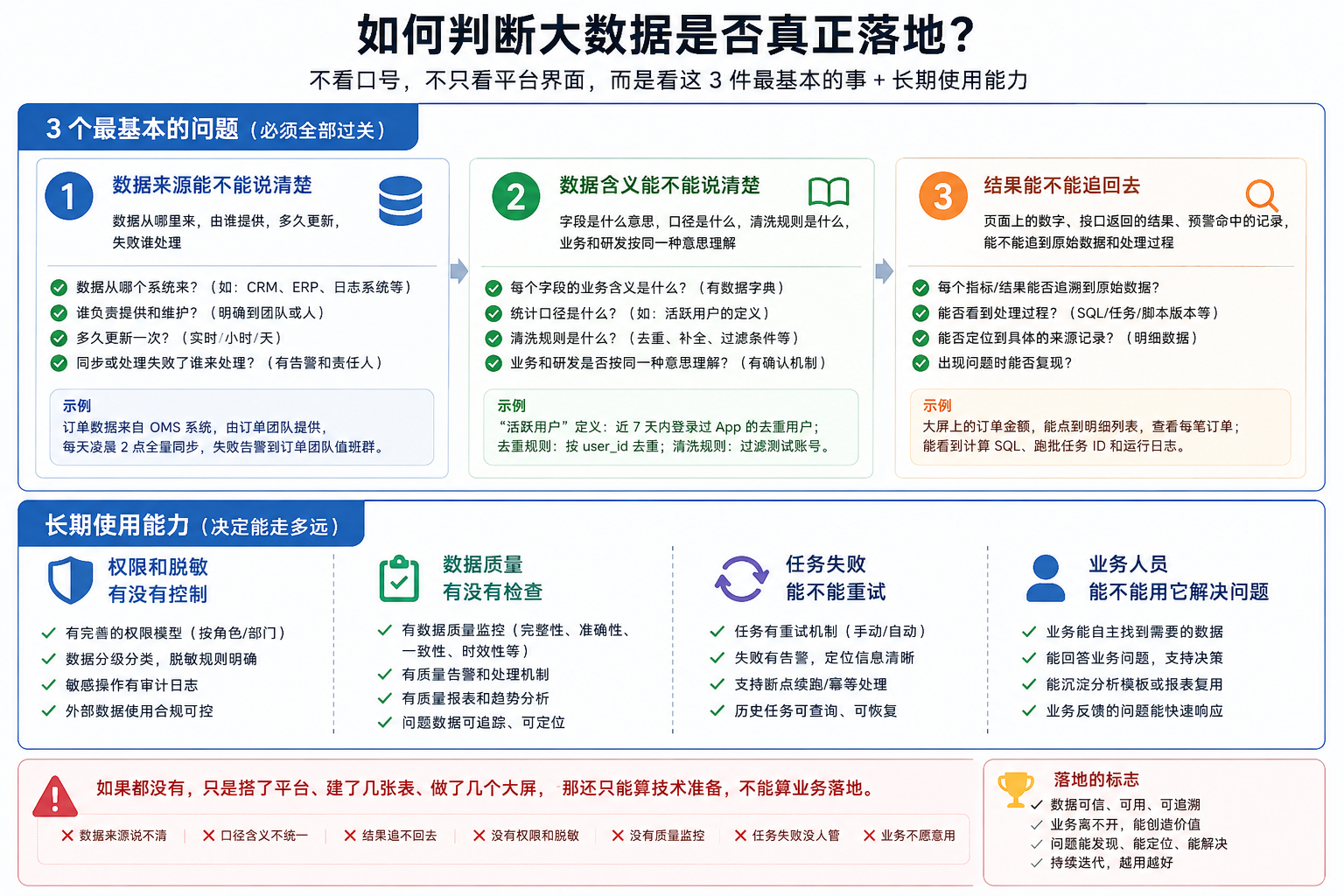
怎么判断大数据有没有真的落地判断大数据有没有真的落地,不看口号,也不只看平台界面。 可以先看 3 个最基本的问题。 第一,数据来源能不能说清楚。 数据从哪个系统来,谁负责提供,多久更新一次,失败了谁处理。 第二,数据含义能不能说清楚。 字段是什么意思,统计口径是什么,清洗规则是什么,业务和研发是不是按同一种意思理解。 第三,结果能不能追回去。 一个页面上的数字、一个接口返回的结果、一条预警命中的记录,能不能追到原始数据和处理过程。 这 3 件事过了,再看长期使用能力。 权限和脱敏有没有控制。 数据质量有没有检查。 任务失败能不能重试。 业务人员能不能用它解决真实问题。 如果这些都没有,只是搭了平台、建了几张表、做了几个大屏,那还只能算技术准备,不能算业务落地。
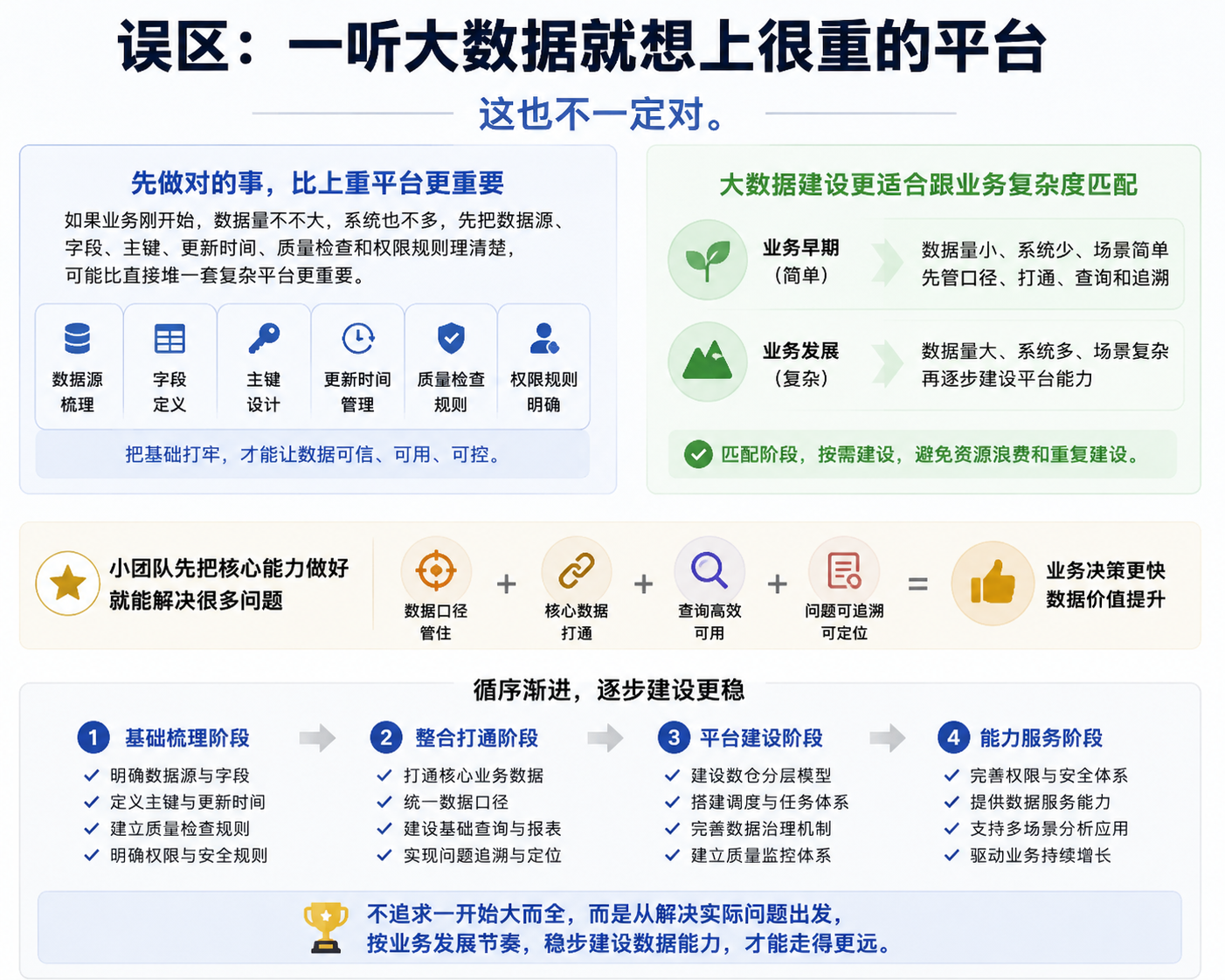
大数据也不用一上来就做很重还有一种误区,是一听大数据就想上很重的平台。 这也不一定对。 如果业务刚开始,数据量不大,系统也不多,先把数据源、字段、主键、更新时间、质量检查和权限规则理清楚,可能比直接堆一套复杂平台更重要。 大数据建设更适合跟业务复杂度匹配。 小团队先把数据口径管住,把核心数据打通,把查询和追溯做好,就已经能解决很多问题。 等数据量、系统数量、分析场景真的起来了,再逐步补数仓、调度、治理、质量、权限和服务能力。 这比一开始就追求大而全更稳。
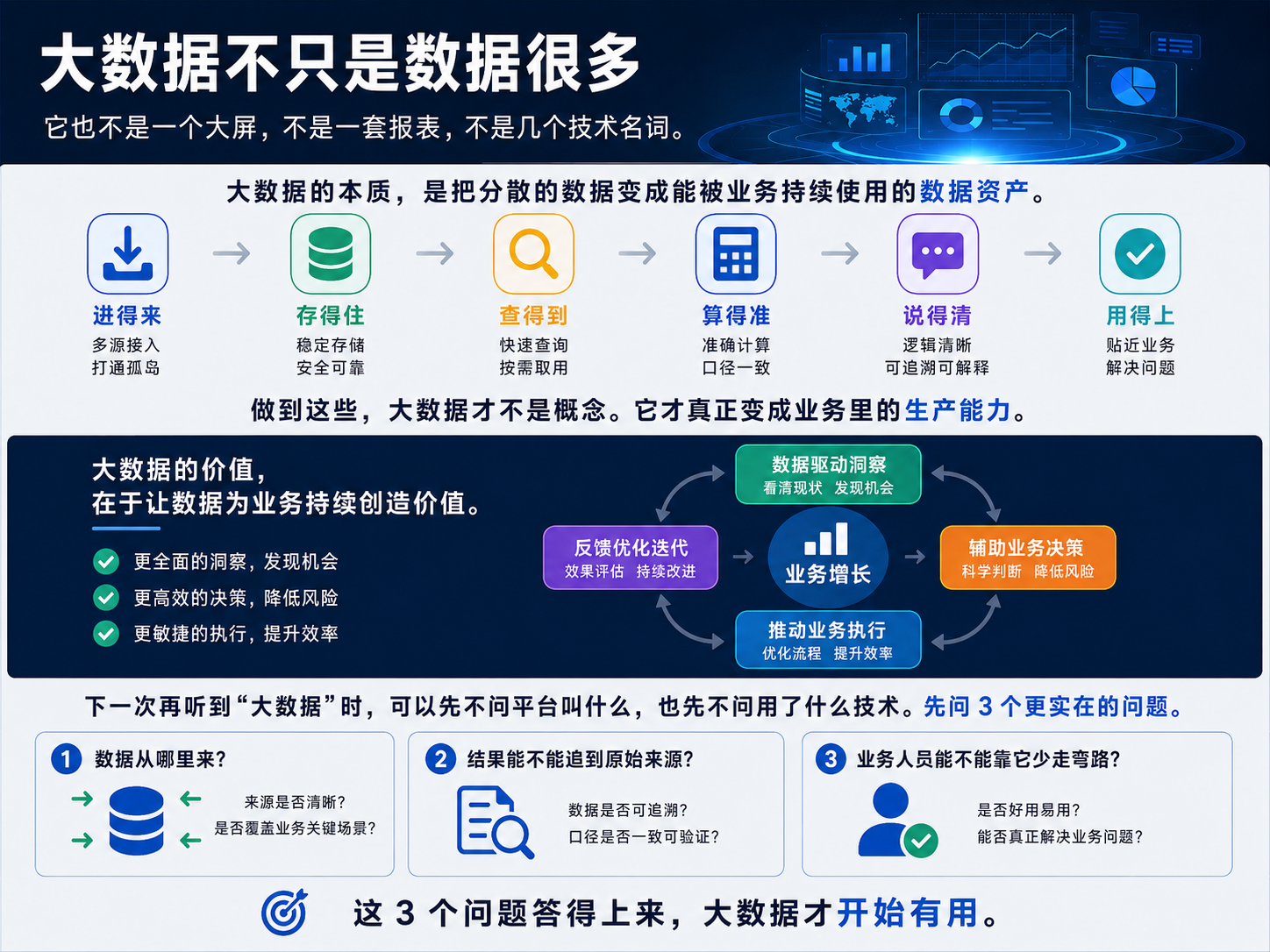
最后再收一下大数据不只是数据很多。 它也不是一个大屏,不是一套报表,不是几个技术名词。 大数据的本质,是把分散的数据变成能被业务持续使用的数据资产。 数据要进得来,存得住,查得到,算得准,说得清,用得上。 做到这些,大数据才不是概念。 它才真正变成业务里的生产能力。 下一次再听到“大数据”时,可以先不问平台叫什么,也先不问用了什么技术。 先问 3 个更实在的问题。 数据从哪里来? 结果能不能追到原始来源? 业务人员能不能靠它少走弯路? 这 3 个问题答得上来,大数据才开始有用。
转自https://www.cnblogs.com/BNTang/p/20026779 该文章在 2026/6/2 8:54:18 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886